
Metaculus and medians
or, Scope-sensitive snafus in summing speculations
previously: Metaculus has some issues
(1)
Should I expect monkeypox to be a big deal for the world? Well, fortunately, Metaculus has a pair of questions that ask users to predict how many infections and deaths there will be in 2022:
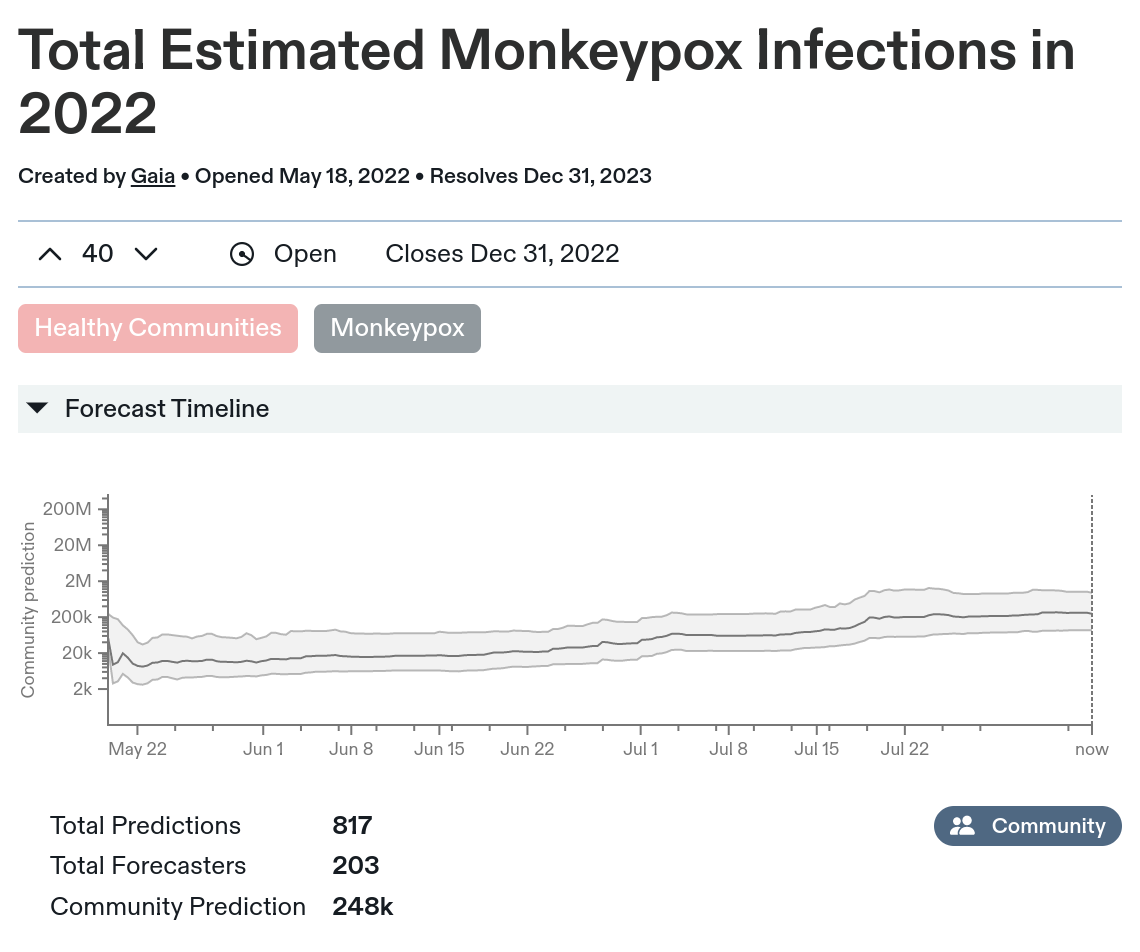
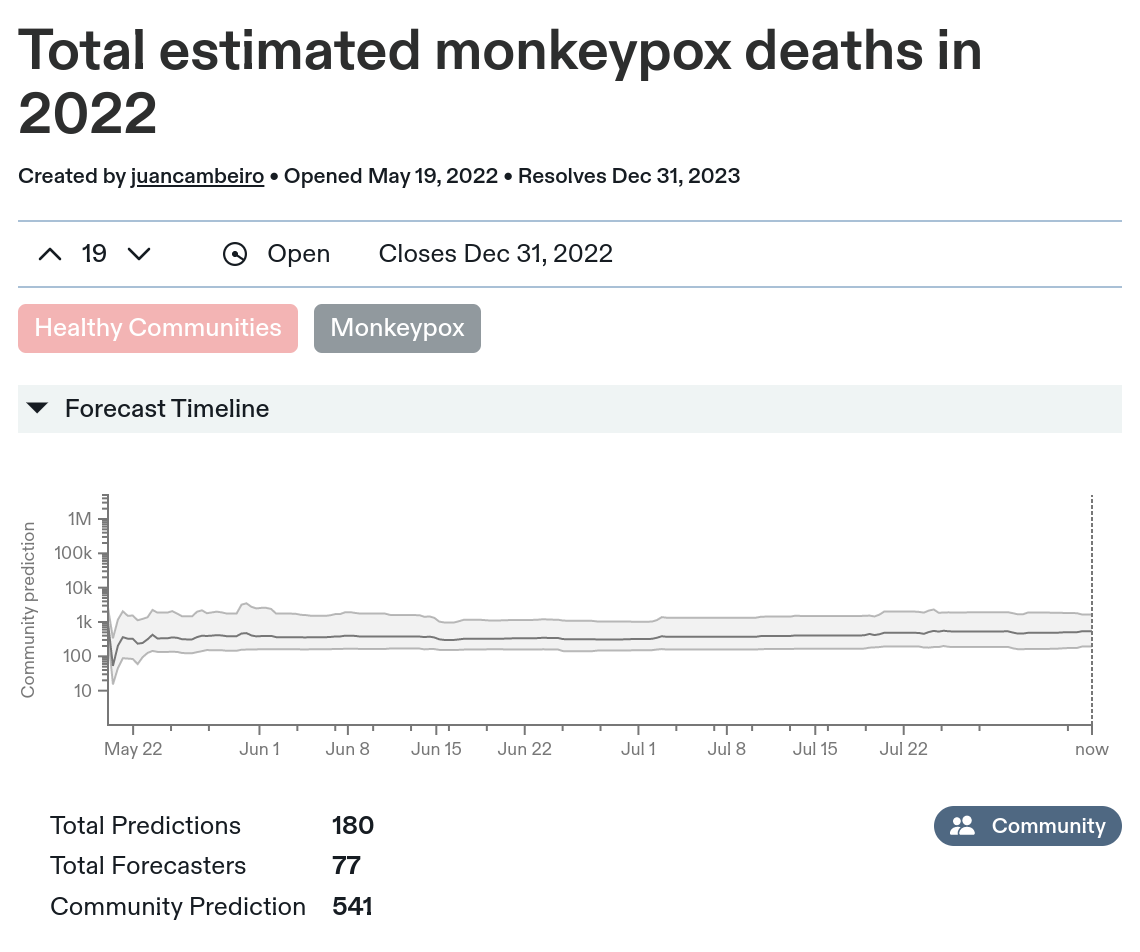
203 users(!) made 817 predictions of infections, and Metaculus helpfully aggregates those into a "community prediction" of ~248k infections. 77 users made 180 predictions of deaths, with a community prediction of 541.
The y-axis is on a log scale (as are the predictors' distributions). This is a good choice! Whatever you expect the most-likely case to be, there's definitely a chance with things like this that one a misestimation or shift in one factor can make it bigger or smaller by a multiple, not just an additive amount.
What's not a good choice is to report the median outcome of the aggregate position as the "community prediction". This causes a headline reported value that is way too low. Like, four to seven times too low (at least for my intended purposes).
Because the predictors gave (and are scored on) probability distributions, Metaculus will happily give you an aggregate distribution, of which the 248k "community prediction" is the median scenario (the middle of the three dashed lines):
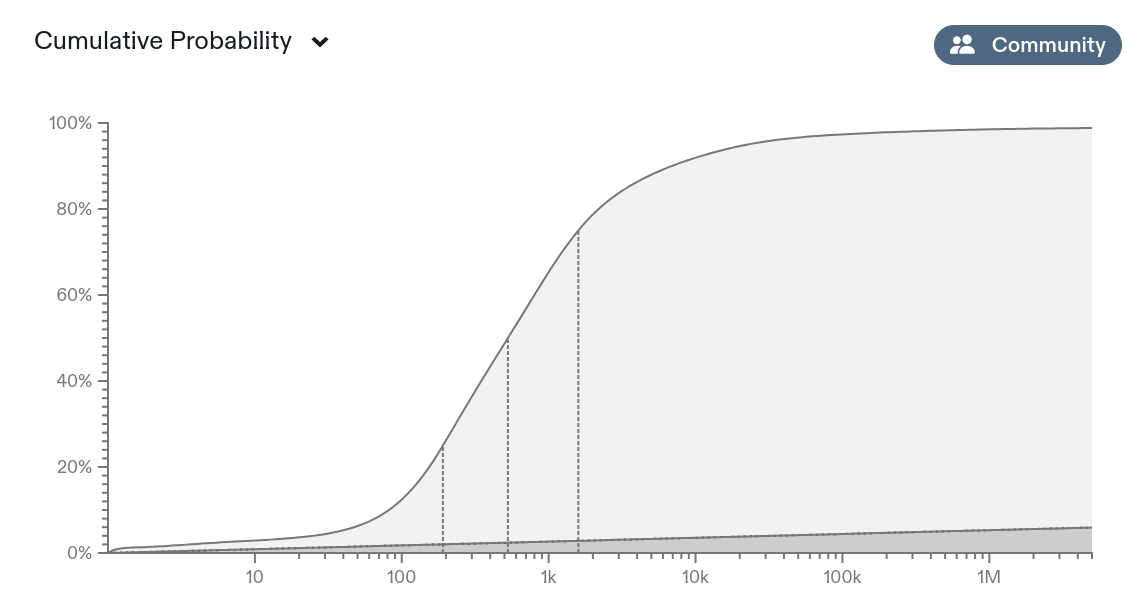
However, on the same plot, the aggregate distribution predicts a 10% chance of at least 4,950k infections. If it's 10% likely to be 5 million infections, then that's already lot more concerning than the 250k in the community prediction! And when I say I'm interested in how much monkeypox to expect, I do mean that in the sense of expected value, and I care about the mean case, not the median case.
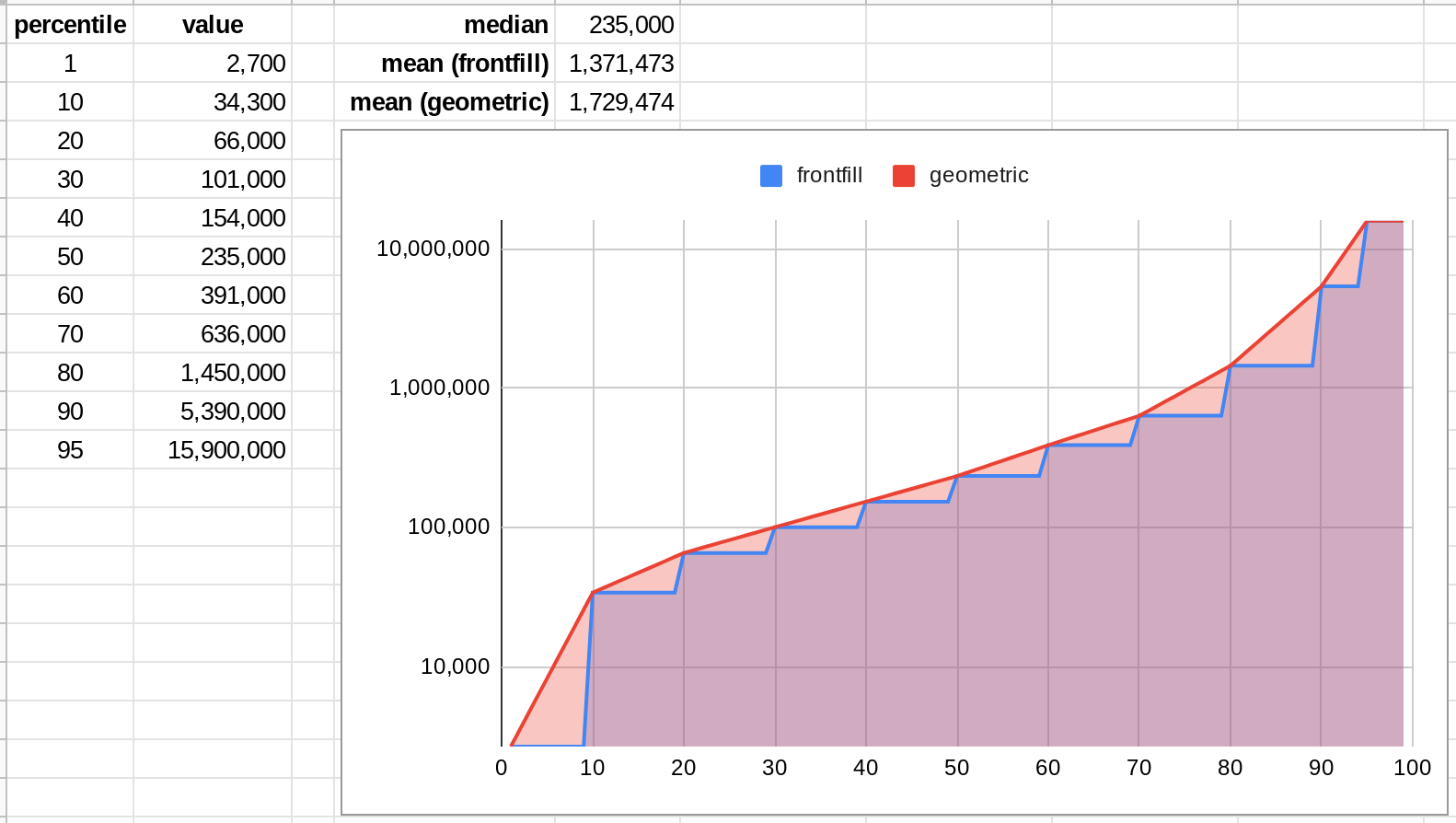
Backing the mean out of the distribution provided on the page takes a small bit of spreadsheet work, but in the end I get 1,729k -- more than 7x higher than the community prediction!
Similarly, monkeypox deaths have a community prediction of 541, but a mean of more like 2,316 (4.3x higher):
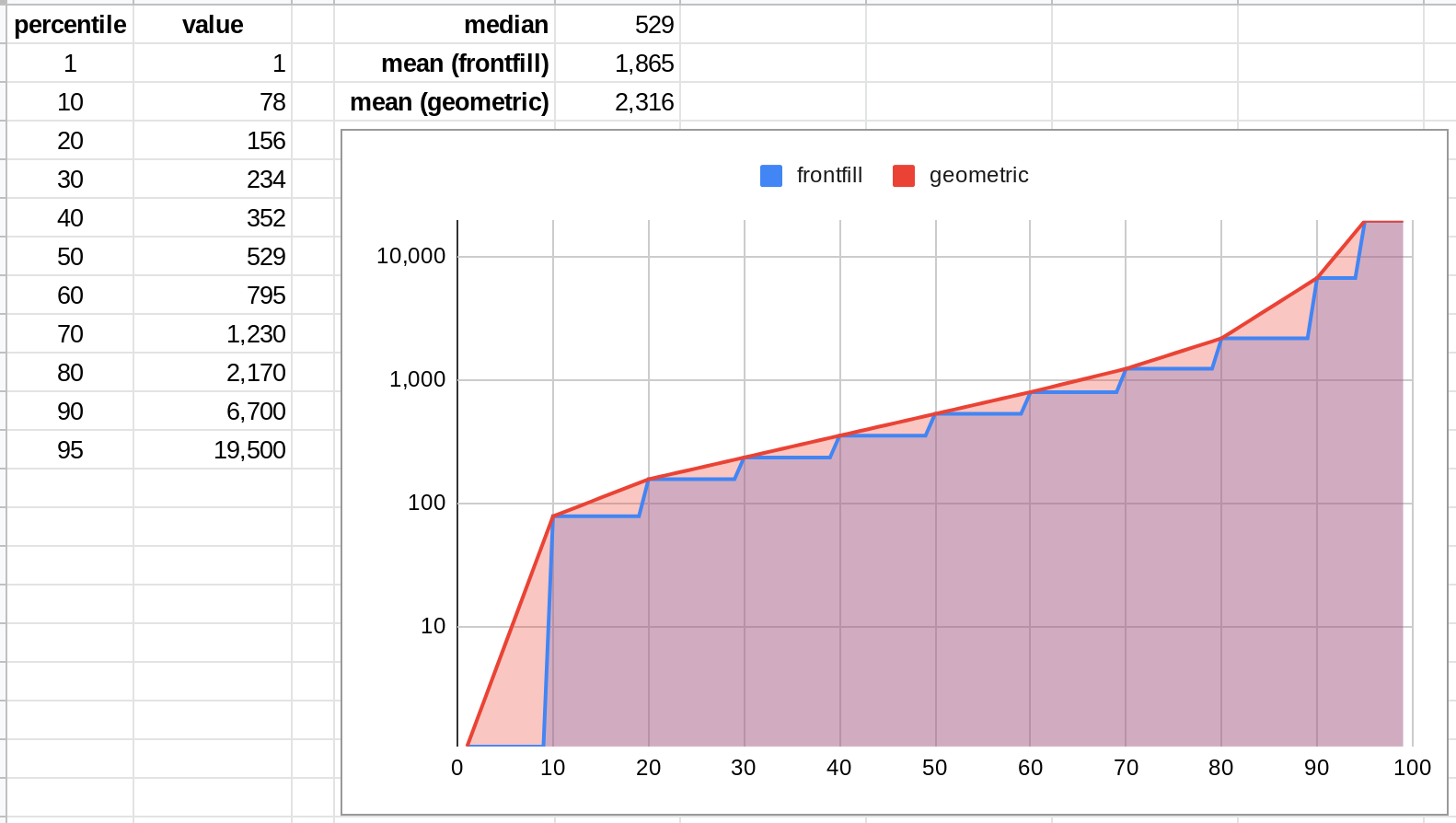
(2)
Now, there are good reasons for Metaculus to report medians instead of means if their goal is to be a respectable-looking site with non-crazy-seeming community predictions at the top of each question. If a Lizardman constant of users predict that there will be 100 times as much of a thing as the truthful users, should Metaculus report a mean that's 5x higher than the non-lizardman consensus? Seems bad!
On the other hand, if you're trying to (1) aggregate actionable knowledge about events on a log scale and (2) aggregate the second-order knowledge that contributors have, I'm not sure you can avoid giving the outlier responders the respect they ask for. It's just that -- as in a prediction market -- you need to make it ruinously bad for them to mess with an otherwise-solid prediction (and you need to make that consequence sting enough that they don't do it unless they do have information to contribute).
A related issue is the one that was raised in the comments of an ACX post on Metaculus from last year:
It's really hard to take metaculus seriously.
e.g. you can't size your bets. That's really bad!
It means that some random person bullshitting on a topic is weighted as much as an expert on it.
e.g. I happen to know that Tether to collapse in 2021 is very likely false and that fair is waaay less than the current market, but there's no way for me to say "I will sell huge size @ 10%". (...)
If the mean of all the predictions is crazy high -- because someone predicts a crazy high number -- should you report it or not? What if that person is willing to double quadruple vigintuble down on their prediction, if you let them?
Well, you can write the aggregation to use "one user, one vote" and take the median, and you'll mostly exclude them, and all the lizardmen, and have more reasonable predictions. Or you can include their contribution, outweighing a lot of carefully-considered near-consensus opinions. Or anything in between.
But if it is the case that the community thinks there's a 5% chance of 15 million infections, and we want the headline number to be useful for planning effective action in the world based on the expected value, then the headline number had better be at least 750k. And if one user wants to stand up and say "I know I'm just one user, but I really know a lot about this, and I want to take all of you on, epistemically speaking", then I'd like to know that! But you won't get there with community medians and well-calibrated quantiles and no mechanism for users to size their bets.
(3)
Once again, I want to be clear that I think that the spirit behind the Metaculus team, and their work, is something to be celebrated. They've gotten hundreds of people together to predict questions about monkeypox! And especially with PredictIt coming under fire, it's good to have all the prediction platforms the Powers That Be will allow us.
But, as I wrote last time, I continue to believe that the prediction community underrates the scoring rule that is used for trillions of dollars of transactions per day: buy or sell at the posted number; get paid based on how linearly right you are, times how much you trade. It doesn't always output probability distributions that are sensible, but neither really does Metaculus.
In my math above, I stopped paying attention to the community distribution at the 95th percentile -- but if you actually believe it all the way through the 99th percentile, you get a mean of 4,695k infections (nearly 19x the "community prediction"!):
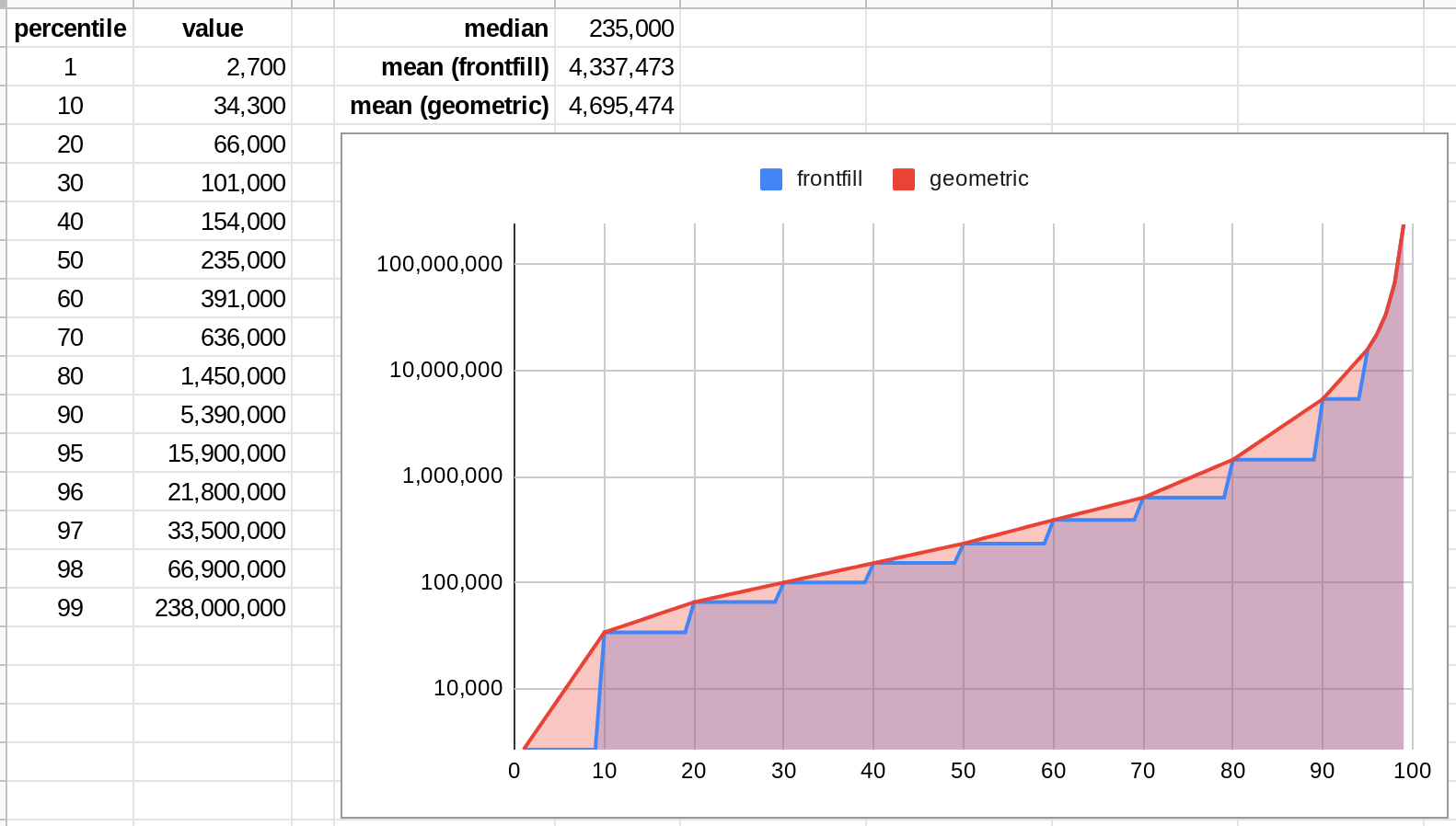
Is that...a good summary of the aggregate state of belief of the contributors? I don't know! I suspect that, in actual practice, it was determined by the choices of predictors who paid careful attention to the bodies of their distribution and very little to the tails. But nearly two-thirds of the expected value comes from the top 5%tile!
An example: On the prediction page, you put in your prediction by specifying a 25%tile, median, and 75%tile case. A user that dials in "My prediction: 743k – 15M" probably isn't thinking too hard about the fact that the mean of the distribution they're expressing is nearly double the top number they specified:
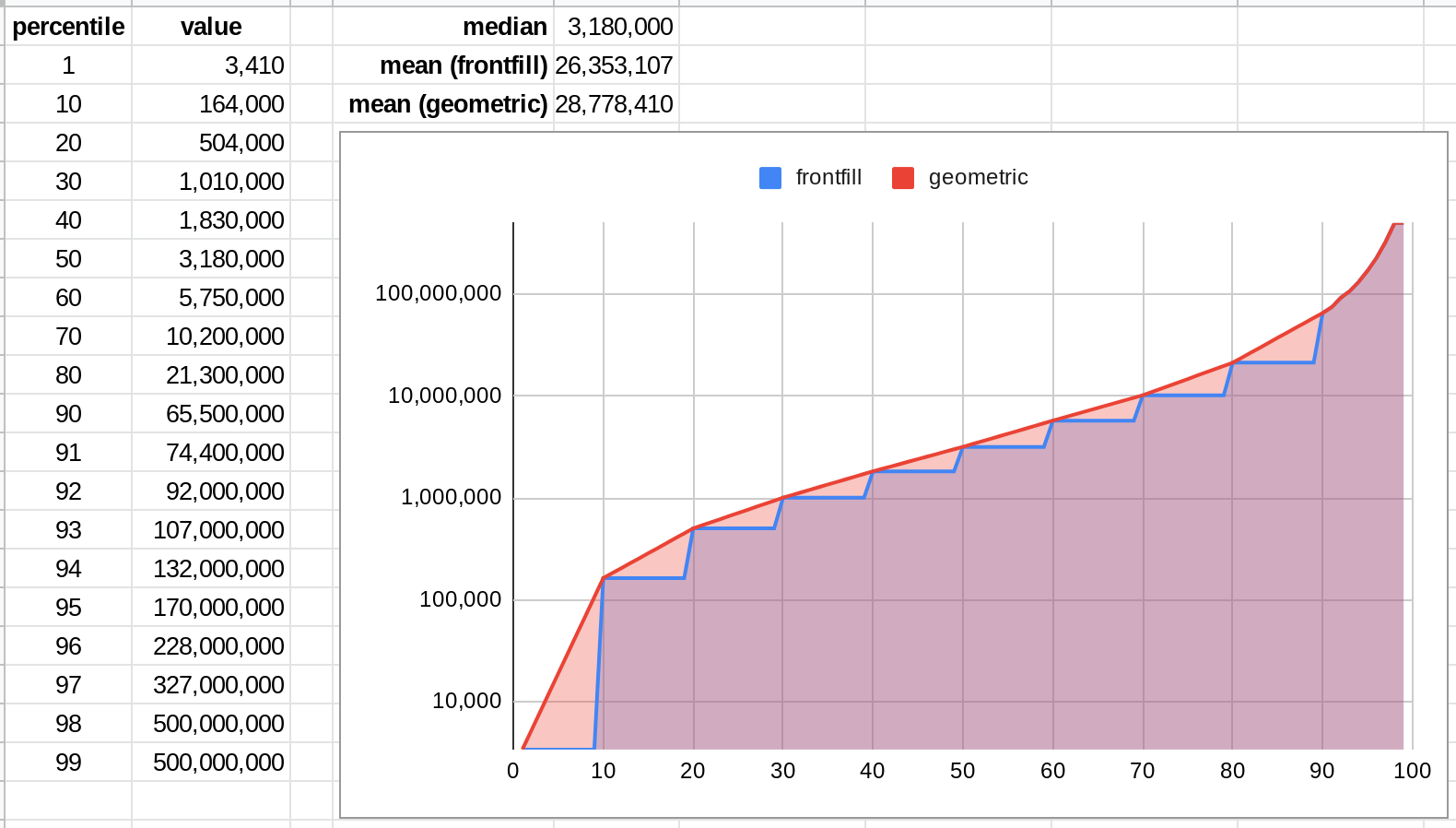
...and similarly, I would be surprised if even 25% of the participants on this quesion have thought specifically about whether the 4.7 million implied by the community distribution is too high or too low. For most of them, they probably didn't even put it in their 25%tile-75%tile interval!
Have the predictors thought whether their 50% confidence interval is correctly calibrated? Probably; that's what the site prompts you to think about. But it's not the thing that a scope-sensitive planner should care the most about when looking at the monkeypox situation. Rather, I'd like a simple readout of the expected number of cases, made by people who are focused on providing -- and incentivized to provide -- estimates of the expected number of cases. Probability distributions are nice to have, but (in my opinion) not if they interfere with users thinking directly about expected values.
Obscuring the upward tails -- and the outlier, would-be-doublers-down predictors -- by aggregating them with a median makes it pretty hard to know what to make of the numbers here. Even if it usually makes the numbers look more sane, most of the time.
Cross-posted to LessWrong, where I'm sure there will be more discussion in the comments.